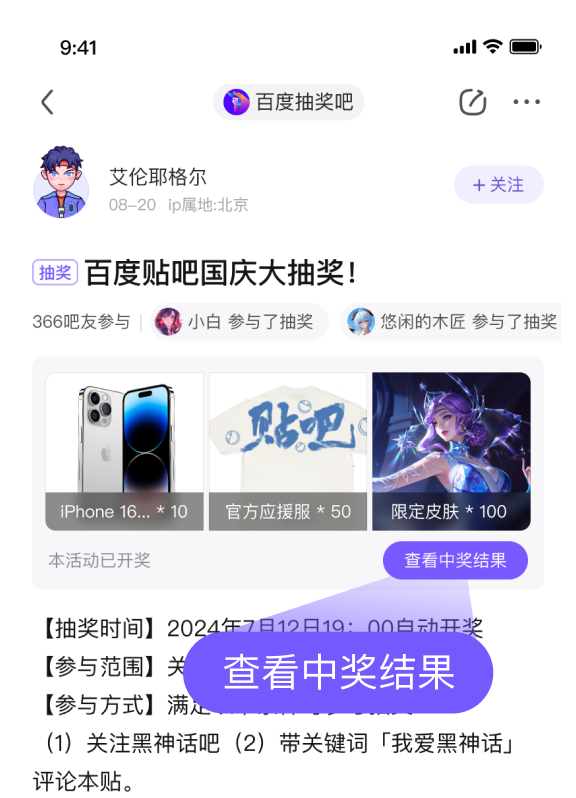
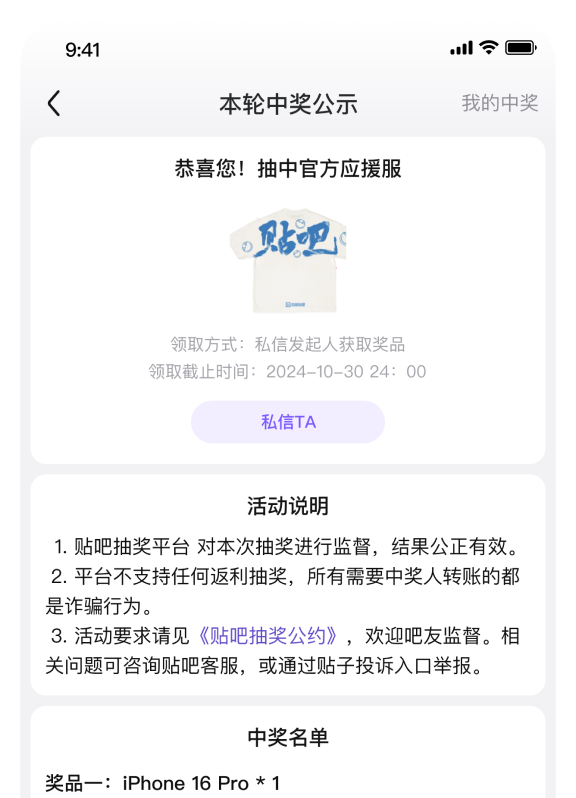
数据优化是机器学习过程中的重要步骤,需要注意多个细节。以下是一些关键点:
1. 数据清洗:这是数据预处理中最重要的部分,包括处理缺失值、异常值和重复值。对于缺失值,可以根据具体情况选择填充(如使用均值、中位数、众数等)或删除该样本。对于异常值,可以使用统计方法或基于规则的方法进行检测和删除。对于重复值,需要找出重复的行并删除。
2. 数据规范化:为了确保模型能够更好地学习数据的特征,需要将数据规范化到统一的标准。常见的规范化方法有最小-最大规范化、Z分数规范化等。
3. 特征选择:选择对目标变量有影响的特征,并去除无关或冗余的特征。这有助于提高模型的精度和减少过拟合。常见的特征选择方法有基于统计的方法、基于模型的方法和包裹式方法等。
4. 平衡数据集:如果数据集中的类分布不均衡,可以使用过采样、欠采样、生成合成样本等方法来平衡数据集。这有助于提高模型的泛化能力。
5. 划分训练集和测试集:将数据集分成训练集和测试集,以便评估模型的性能。常见的划分方法有随机划分、分层抽样等。
6. 选择合适的模型:根据数据的特性和问题的类型,选择合适的机器学习模型。例如,对于分类问题,可以选择逻辑回归、支持向量机、决策树等模型;对于回归问题,可以选择线性回归、神经网络等模型。
总之,数据优化是机器学习中不可或缺的一步,需要注意数据清洗、规范化、特征选择、平衡数据集、划分训练集和测试集等方面。正确的数据优化可以显著提高模型的性能和泛化能力。
1. 数据清洗:这是数据预处理中最重要的部分,包括处理缺失值、异常值和重复值。对于缺失值,可以根据具体情况选择填充(如使用均值、中位数、众数等)或删除该样本。对于异常值,可以使用统计方法或基于规则的方法进行检测和删除。对于重复值,需要找出重复的行并删除。
2. 数据规范化:为了确保模型能够更好地学习数据的特征,需要将数据规范化到统一的标准。常见的规范化方法有最小-最大规范化、Z分数规范化等。
3. 特征选择:选择对目标变量有影响的特征,并去除无关或冗余的特征。这有助于提高模型的精度和减少过拟合。常见的特征选择方法有基于统计的方法、基于模型的方法和包裹式方法等。
4. 平衡数据集:如果数据集中的类分布不均衡,可以使用过采样、欠采样、生成合成样本等方法来平衡数据集。这有助于提高模型的泛化能力。
5. 划分训练集和测试集:将数据集分成训练集和测试集,以便评估模型的性能。常见的划分方法有随机划分、分层抽样等。
6. 选择合适的模型:根据数据的特性和问题的类型,选择合适的机器学习模型。例如,对于分类问题,可以选择逻辑回归、支持向量机、决策树等模型;对于回归问题,可以选择线性回归、神经网络等模型。
总之,数据优化是机器学习中不可或缺的一步,需要注意数据清洗、规范化、特征选择、平衡数据集、划分训练集和测试集等方面。正确的数据优化可以显著提高模型的性能和泛化能力。